
I gave this talk at JSFoo, Bengaluru, in October 2018. It describes my experience in switching to ReasonML on the Turaku project and how learning to use a statically-typed functional programming language involves much more than learning the language's syntax or features.
You can find the complete set of slides on Slideshare.
I'd like to thank Rekha for the last minute work that she did in replacing my awful stick figures with prettier ones, and Jasim and Sherin of Protoship, for their critique and advice in the process of creating this talk. Credit is also due to the fine folks over at HasGeek for setting up rehearsals; I'm pretty sure the talk wouldn't have gone as well as it did without those.
ReasonML: Strict, powerful and forgiving
I've been working on a personal project for a little under a year now - a password management tool for teams. I started work on it because I looked at nearly every password manager out there and there was something or the other about all of them that ticked me off. Something that I thought could have been done better, or something that I just plain hated.
So I decided to build a new one. Why not? I've been building web applications for years now. How hard can a password manager be? So, I picked libraries and tooling that I was familiar with. I wanted an application that could run on the desktop, so I picked React & Electron to build a front-end, and Ruby on Rails for the API.
Turns out, it's not as easy as I thought it'd be.
After a few months of work, the front-end was giving me trouble. I noticed that adding new features, and refactoring was becoming a pain. Since I was building a proof-of-concept, I hadn't bothered with tests, and adding new features was becoming more and more stressful.
So I was faced with a choice. Either I start writing tests, and do TDD, or something akin to that going forward, or I try out something that I'd been hearing about for a while from what felt like all directions:

“Introduce static types!” It was something I had practically no experience with, but something I'd been hearing a lot about, and it seemed cool, so I thought, why not? I might as well learn something totally new while I'm at it.
So I shopped around, and I found four choices for me at the time: Typescript and Flow, if I wanted to keep my codebase intact, and gradually introduce typing, or switch to ReasonML, or Elm, and rewrite what I'd already created.
I ended up choosing ReasonML because of a couple of things:
- I liked how the syntax looked and felt. It was very familiar, and yet, it was also exciting because there were these new things that I'd never used before.
- The person who started the Reason project is Jordan Walke - the creator of React, and I love using React.
- But most importantly, I had two friends who had been working with ReasonML for over a year at that point, and I knew they'd step in and help me if I got stuck at some point. And I knew that that would happen, given that I'd never really tried functional programming, or used static types before.

Which brings us to Reason. Its syntax looks like Javascript, but it isn't Javascript. Turns out it's actually OCaml, a twenty year old language, which itself is derived from the 45-year-old Meta-language - making it a member of the ML family of languages. So a lot of work has gone into OCaml over time, and it has a lot of features that I'd never used before.
And there's a project on OCaml called Bucklescript, which was built at Bloomberg, that converts OCaml to Javascript. And the key part of the conversion is that it generates some very readable Javascript, as you'll see in some examples in a bit.
So ReasonML is actually a Javascript-like syntax for OCaml, and its tool-chain converts Reason code to OCaml, which then uses a tool called Bucklescript to convert that OCaml to Javascript. That looks complicated, but the good part is the tool-chain is so good that we neither see, nor need to worry about all the shenanigans that's happening behind the scenes.

How hard is it to get started? Not at all. Reason's tool-chain is also based around the Node ecosystem.
These two commands are all you need to run to get a minimum working Reason development environment.
Since most of you are Javascript developers, I think there's a high likelihood that you're using VSCode as your editor, or at least have it installed. So after this step here, installing the Reason plugin for VSCode gives you superb editor integration.
So now that we've got all the initial stuff out of our way, let's take a look at some Reason code, and see how it's different from Javascript.

First, and most obviously, ReasonML is statically typed. If a program compiles, then every binding has a type, even if we haven't specified anything. Because Reason has a type inference mechanism that is really intelligent.
From my experience with it, the best way to characterize the type system is that it feels like a person is sitting and trying to figure out what the types could be. It works really well, almost all the time.
When we look at the code here, we know that car is a string. So does Reason, there's no need to specify its type. You can see that the Javascript output from the Reason toolchain is also pretty simple. After all, we're not doing much here.

Reason also has something that looks like objects in Javascript. In fact, in this example, it looks exactly the same as it would in Javascript. In Reason, they're called records.
What's different about records is that they need to have an explicit type definition.
You don't however need to specify that myFirstCar is a vehicle. We can tell the type from looking at the code; so can Reason.
Surprisingly, on the Javascript side, records are being represented using an array instead of a JS object. This is done for performance reasons - however, you should note that Bucklescript still leaves helpful comments in-line to ensure that the generated code is still readable.
You'll also note that, there's no type information on the JS side. The type info is something that the compiler uses to make sure that there are no mistakes in what we've written. If the code compiles, then it's because it has a 100% certainty that every single one of the values and functions in our code uses the correct types.
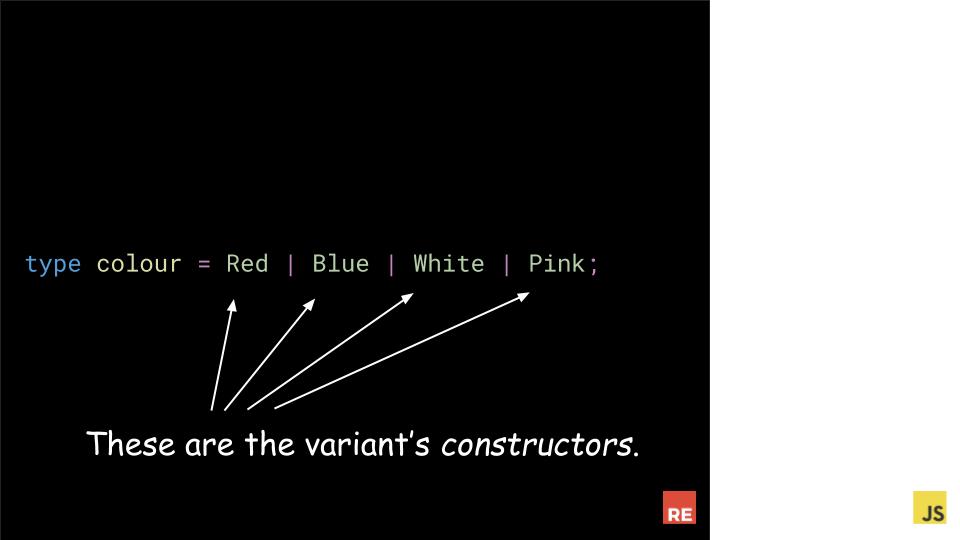
Reason also has another feature that absolutely blew my mind the first time I used it - Variants. Variants allow us to model different possibilities in a way I never had in any dynamically typed language.
We can define colour as a variant, that is either Red, Blue,White, or Pink. In Reason, each of these values is called a constructor.

Let's use variants to try and improve the previous example.
Using variants for colour, make and model lets us use the constructors in place of strings, and now on the Javascript side, you'll notice that, instead of being an array of strings, the output is an array of integers. This sort of conversion is something that the compiler can make accurately for performance benefits. Note that it still leaves comments in-line for readability.

The mind-blowing part of variants is when we pattern-match on them with switch. ThisproductionRun function, given a car, returns the production run for the model of the car. switch allows us to pattern-match things against their possible values. Note how there's no return statement. In Reason, the final expression mentioned in a function body is return value.
You'll also note that's there's some weird stuff in the JS output now.
That's because we're ignoring a warning from the compiler telling us thatwe've forgotten to handle two possible values here: Ambassador & Zen. The compiler is aware there is a possibility that the function will fail, because the pattern matching in the function is not exhaustive. By default, it will issue a warning that the pattern-matching doesn't cover every possibility.
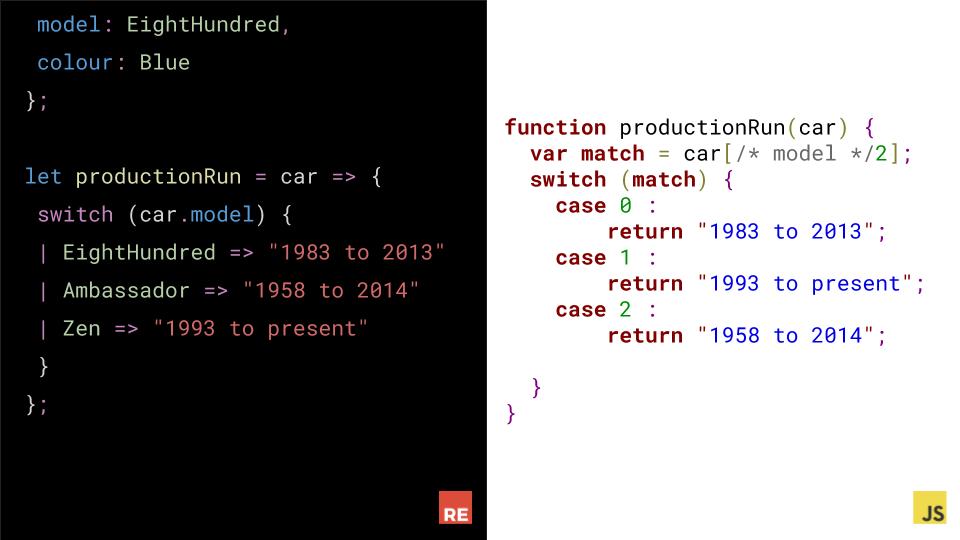
If we follow the compiler's instruction and write the function as it should have been written in the first place, you'll see that the JS output is much cleaner, with a simple switch-case.

Assuming that you use variants to describe different possibilities for values in your code, this removes a lot of over-head in terms of what you, as a developer, need to keep in mind when you're making changes. Because the compiler will remind you, if you make mistakes.
You can (and also should) configure the compiler to treat mistakes like these as errors instead of warnings - so it won't even generate any Javascript code unless you've handled all of the possibilities that you've defined in your code.

So because we have a compiler checking for possibilities that you might have forgotten to handle, these variant types are already useful. They're not perfect, though, because with these types, we can do something like this:
This compiles, but is very odd, because I've never seen a pink Ambassador on the road.
They exist, sure. There's nothing stopping you from painting an Ambassador pink, questionable as the choice may be. But pink was certainly never a production colour for that model.

While the previous example was within the realm of possibility, this one's a bit different.
That's just plain wrong. Maruti, the manufacturer, is never going to make an Ambassador. But it still compiles, because as far as the compiler's concerned, a car is simply a record with these three separate values.
But they're not really separate are they? They're related to each other. Cars of a make could be one of a few models, and depending on the model, they may be available in a set of colours.
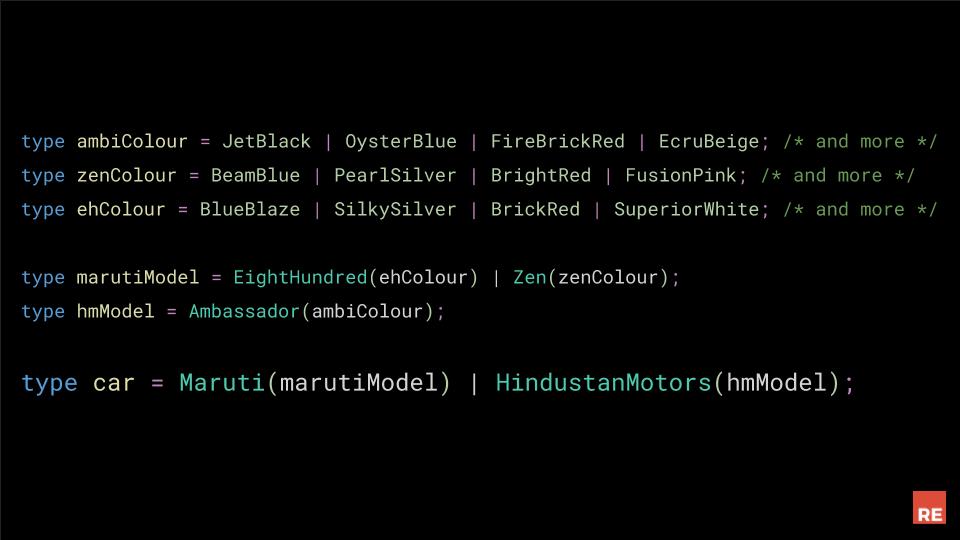
ReasonML variants have a feature that allows us to represent this sort of nested relationship. We can write this by giving variant constructors arguments, as shown here.
We have three sets of colours, one for each model, and there are two model variants, one for each manufacturer, and each of its constructor specifies that a model requires its corresponding colour as an argument.
And now that the properties have a nested relationship, we can simply say that a car variant is one of two makes, each accepting a matching model variant.
In this example, variant constructors have only one argument, and they're also variants, but constructors can have any number of arguments, and they can be any type, so you put rich information in there, like records, or arrays.
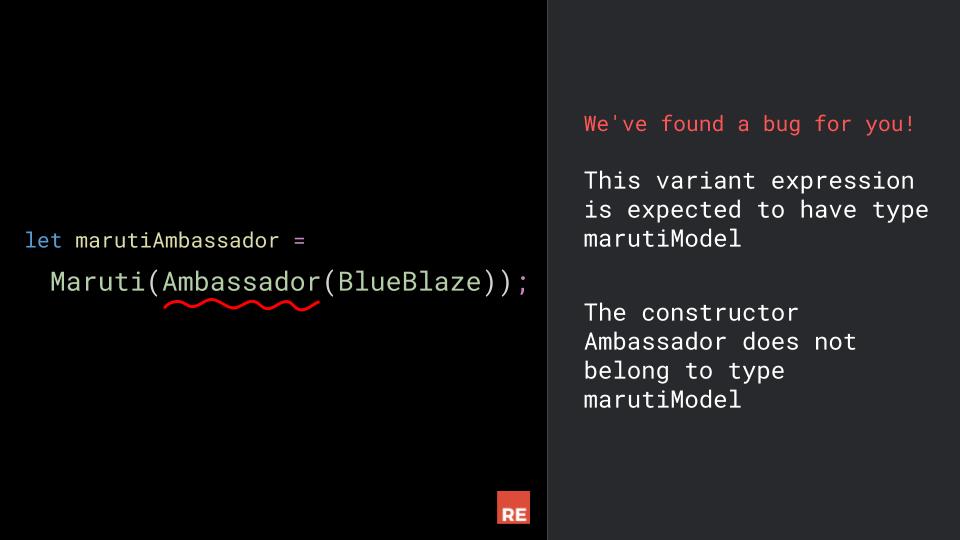
Now, with this type structure, is is possible to create a pink Ambassador? Or a pink Maruti Ambassador? No, you can't.
You are only allowed to write correct combinations.
This process that I just demonstrated is a pattern that you'll find applied again and again in functional programming languages, and those with strong type systems, and it's called...

When types are written correctly, it can prevent you, the developer, from even writing an invalid data structure. A lot of our errors happen because our applications go into an invalid state. Types, used correctly, can make that impossible - because with a perfect type structure you literally cannot make mistakes.
So this approach takes care of data that we define inside ReasonML. Now we need to wonder whether this idea affects how we handle user input. You see, data could come from outside Reason in unexpected ways.

Assume that's there a UI which allows the user to select the properties of the car. Because the UI isn't well designed, it allows the selection of any combination of values. So if the user were to submit a form like this, we could presumably expect our application to end up with three random string values.
However, remember that functions in our code will use our custom type car. If we want to pass this data around in our Reason code, we'll first want to fit this into our Reason data structure, with its strong type that we created earlier.
The whole point of creating that data type was to make sure illegal states were impossible. So how are we going to map this data to the vehicle type?
The short answer is that you can't. There is no conceivable way that invalid data is going to turn into a valid car. So what can we do here? What are we supposed to do here?

So where am I going with this? Let's do a short recap. We've built a type car with the explicit purpose of never being in an illegal state. We call this pattern make illegal states unrepresentable. We did this by using a ReasonML language feature calledvariants, and by relying on the ReasonML compiler to block us from creating invalid data.
But because we did this, we can't just naively fit user input into our data types. We need to parse them and handle unexpected data properly. What you'll really want to do when you get data from the outside world, and you will get invalid data from the outside world, is to properly parse that data and to handle every single edge case.
This is another pattern, and I'm calling this parse all external data & enforce boundaries.
I'm not going to go into detail into how this pattern can be implemented, but suffice to say that we can do it by using ReasonML's pattern-matching feature, which we very briefly saw in one of the examples, and by writing parser functions that use pattern-matching.
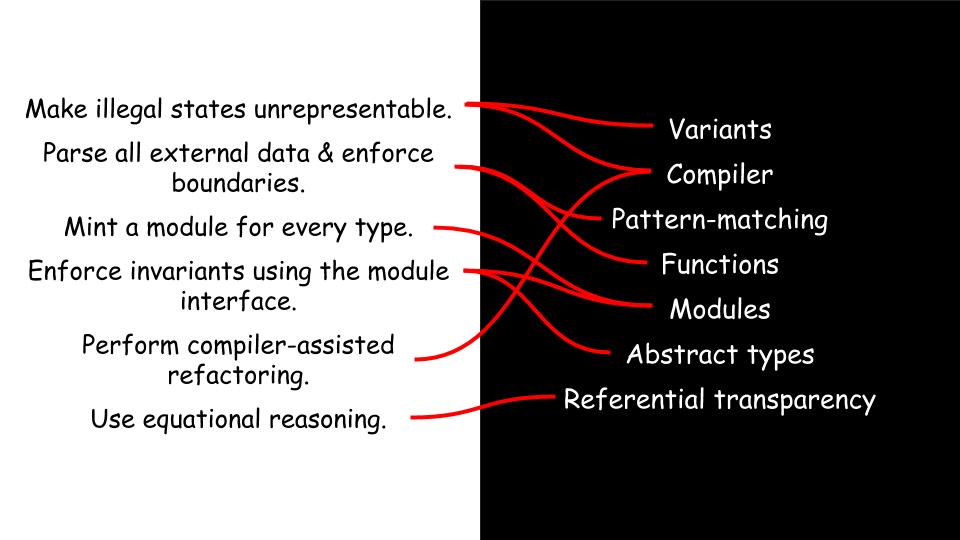
So we started with one pattern, and ended with two, and both patterns are enabled by language features that ReasonML provides. However, there are more patterns.
And this is certainly not exhaustive list - just a few things that I'm aware of. These patterns are enabled by the presence of language features - features that are only really available if you're using a strongly typed language.

When someone talks about learning a functional language like ReasonML, they don't mean getting used to the syntax, or even the language features. Those are relatively easy to learn. These patterns should be what you're looking to pick up.
I believe that building a repertoire of such patterns is what makes us better developers. If we can think of language features as the tools that we use to do our work, then we can also think of these patterns as the techniques that we learn to use the tools properly.
Understanding new techniques improves our ability, our craft, and the quality of the applications that we make.
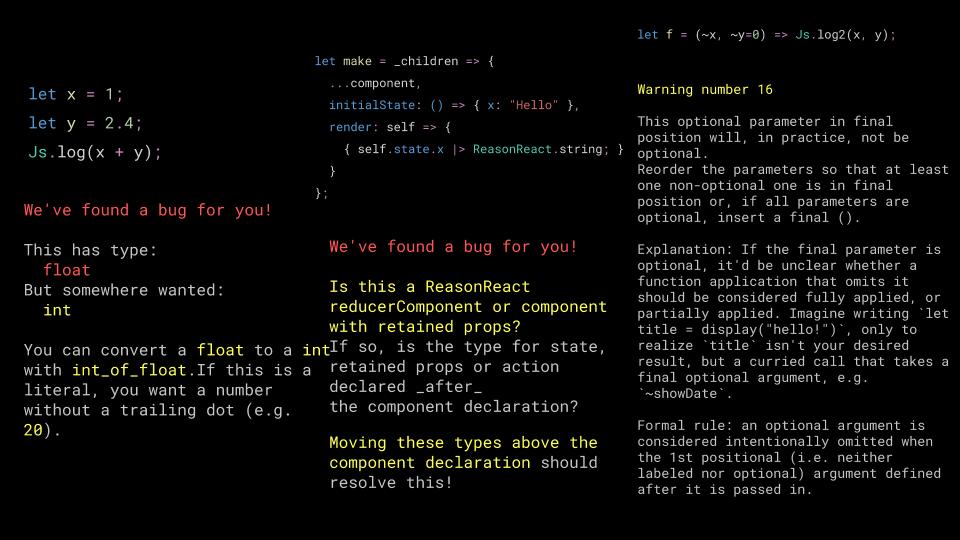
I believe that ReasonML is a kinder language than Javascript. Yes, it is a stricter language, requiring us to observe more care when we write programs, but it is also more forgiving. It doesn't really let us make mistakes - it prevents what it can, but it also gives you really great advice on how to fix mistakes when you, inevitably make them.
What you really want to be focused on when you're learning a functional language are those patterns that I just mentioned, and I've personally found ReasonML to be a kind, forgiving companion in that journey.
Give it a try - I can guarantee that you'll learn something.

Here's a timestamped link of the video footage (12 minutes)!